



Originally Posted on “SEO” – Google News by James Brockbank
Lots of insights and opinions have already been shared about last week’s leak of Google’s Content API Warehouse documentation, including the fantastic write-ups from:
But what can link builders and digital PRs learn from the documents?
Since news of the leak broke, Liv Day, Digitaloft’s SEO Lead, and I have spent a lot of time investigating what the documentation tells us about links.
We went into our analysis of the documents trying to gain insights around a few key questions:
- Do links still matter?
- Are some links more likely to contribute to SEO success than others?
- How does Google define link spam?
To be clear, the leaked documentation doesn’t contain confirmed ranking factors. It contains information on more than 2,500 modules and over 14,000 attributes.
We don’t know how these are weighted, which are used in production and which could exist for experimental purposes.
But that doesn’t mean the insights we gain from these aren’t useful. So long as we consider any findings to be things that Google could be rewarding or demoting rather than things they are, we can use them to form the basis of our own tests and come to our own conclusions about what is or isn’t a ranking factor.
Below are the things we found in the documents that link builders and digital PRs should pay close attention to. They’re based on my own interpretation of the documentation, alongside my 15 years of experience as an SEO.
1. Google is probably ignoring links that don’t come from a relevant source
Relevancy has been the hottest topic in digital PR for a long time, and something that’s never been easy to measure. After all, what does relevancy really mean?
Does Google ignore links that don’t come from within relevant content?
The leaked documents definitely suggest that this is the case.
We see a clear anchorMismatchDemotion referenced in the CompressedQualitySignals module:

While we have little extra context, what we can infer from this is that there is the ability to demote (ignore) links when there is a mismatch. We can assume this to mean a mismatch between the source and target pages, or the source page and target domain.
What could the mismatch be, other than relevancy?
Especially when we consider that, in the same module, we also see an attribute of topicEmbeddingsVersionedData.

Topic embeddings are commonly used in natural language processing (NLP) as a way of understanding the semantic meaning of topics within a document. This, in the context of the documentation, means webpages.
We also see a webrefEntities attribute referenced in the PerDocData module.

What’s this? It’s the entities associated with a document.
We can’t be sure exactly how Google is measuring relevancy, but we can be pretty certain that the anchorMismatchDemotion involves ignoring links that don’t come from relevant sources.
The takeaway?
Relevancy should be the biggest focus when earning links, prioritized over pretty much any other metric or measure.
2. Locally relevant links (from the same country) are probably more valuable than ones from other countries
The AnchorsAnchorSource module, which gives us an insight into what Google stores about the source page of links, suggests that local relevance could contribute to the link’s value.
Within this document is an attribute called localCountryCodes, which stores the countries to which the page is local and/or the most relevant.

It’s long been debated in digital PR whether links coming from sites in other countries and languages are valuable. This gives us some indication as to the answer.
First and foremost, you should prioritize earning links from sites that are locally relevant. And if we think about why Google might weigh these links stronger, it makes total sense.
Locally relevant links (don’t confuse this with local publications that often secure links and coverage from digital PR; here we’re talking about country-level) are more likely to increase brand awareness, result in sales and be more accurate endorsements.
However, I don’t believe links from other locales are harmful. More than those where the country-level relevancy matches are weighted more strongly.
3. Google has a sitewide authority score, despite claiming they don’t calculate an authority measure like DA or DR
Maybe the biggest surprise to most SEOs reading the documentation is that Google has a “site authority” score, despite stating time and time again that they have no measure that’s like Moz’s Domain Authority (DA) or Ahrefs’ Domain Rating (DR).
In 2020, Google’s John Mueller stated:
- “Just to be clear, Google doesn’t use Domain Authority *at all* when it comes to Search crawling, indexing, or ranking.”
But later that year, did hint at a sitewide measure, saying about Domain Authority:
- “I don’t know if I’d call it authority like that, but we do have some metrics that are more on a site level, some metrics that are more on a page level, and some of those site-wide level metrics might kind of map into similar things.”
Clear as day, in the leaked documents, we see a SiteAuthority score.
To caveat this, though, we don’t know that this is even remotely in line with DA or DR. It’s also likely why Google has typically answered questions in the way they have about this topic.
Moz’s DA and Ahrefs’ DR are link-based scores based on the quality and quantity of links.
I’m doubtful that Google’s siteAuthority is solely link-based though, given that feels closer to PageRank. I’d be more inclined to suggest that this is some form of calculated score based on page-level quality scores, including click data and other NavBoost signals.
The likelihood is that, despite having a similar naming convention, this doesn’t align with DA and DR, especially given that we see this referenced in the CompressedQualitySignals module, not a link-specific one.
4. Links from within newer pages are probably more valuable than those on older ones
One interesting finding is that links from newer pages look to be weighted more strongly than those coming from older content, in some cases.
We see reference to sourceType in the context of anchors (links), where the quality of a link’s source page is recorded in correlation to the page’s index tier.
What stands out here, though, is the reference to newly published content (freshdocs) being a special case and considered to be the same as “high quality” links.
We can clearly see that the source type of a link can be used as an importance indicator, which suggests that this relates to how links are weighted.
What we must consider, though, is that a link can be defined as being “high quality” without being a fresh page, it’s just that these are considered the same quality.
To me, this backs up the importance of consistently earning links and explains why SEOs continue to recommend that link building (in whatever form, that’s not what we’re discussing here) needs consistent resources allocated. It needs to be an “always-on” activity.
5. The more Google trusts a site’s homepage, the more valuable links from that site probably are
We see a reference within the documentation (again, in the AnchorsAnchorSource module) to an attribute called homePageInfo, which suggests that Google could be tagging link sources as not trusted, partially trusted or fully trusted.

What this does define is that this attribute relates to instances when the source page is a website’s homepage, with a not_homepage value being assigned to other pages.
So, what could this mean?
It suggests that Google could be using some definition of “trust” of a website’s homepage within the algorithms. How? We’re not sure.
My interpretation: internal pages are likely to inherit the homepage’s trustworthiness.
To be clear: we don’t know how Google defines whether a page is fully trusted, not trusted or partially trusted.
But it would make sense that internal pages inherit a homepage’s trustworthiness and that this is used, to some degree, in the weighting of links and that links from fully trusted sites are more valuable than those from not trusted ones.
Interestingly, we’ve discovered that Google is storing additional information about a link when it is identified as coming from a “newsy, high quality” site.

Does this mean that links from news sites (for example, The New York Times, The Guardian or the BBC) are more valuable than those from other types of site?
We don’t know for sure.
But when looking at this – alongside the fact that these types of sites are typically the most authoritative and trusted publications online, as well as those that would historically had a toolbar PageRank of 9 or 10 – it does make you think.
What’s for sure, though, is that leveraging digital PR as a tactic to earn links from news publications is undoubtedly incredibly valuable. This finding just confirms that.
7. Links coming from seed sites, or those links to from these, are probably the most valuable links you could earn
Seed sites and link distance ranking is a topic that doesn’t get talked about anywhere near as often as it should, in my opinion.
It’s nothing new, though. In fact, it’s something that the late Bill Slawski wrote about in 2010, 2015 and 2018.
The leaked Google documentation suggests that PageRank in its original form has long been deprecated and replaced by PageRank-NearestSeeds, referenced by the fact it defines this as the production PageRank value to be used. This is perhaps one of the things that the documentation is the clearest on.

If you’re unfamiliar with seed sites, the good news is that it isn’t a massively complex concept to understand.
Slawski’s articles on this topic are probably the best reference point for this:
“The patent provides 2 examples [of seed sites]: The Google Directory (It was still around when the patent was first filed) and the New York Times. We are also told: ‘Seed sets need to be reliable, diverse enough to cover a wide range of fields of public interests & well connected to other sites. In addition, they should have large numbers of useful outgoing links to facilitate identifying other useful & high-quality pages, acting as ‘hubs’ on the web.’
“Under the PageRank patent, ranking scores are given to pages based upon how far away they might be from those seed sets and based upon other features of those pages.”– Bill Slawski, PageRank Update (2018)
8. Google is probably using ‘trusted sources’ to calculate whether a link is spammy
When looking at the IndexingDocjoinerAnchorSpamInfo module, one that we can assume relates to how spammy links are processed, we see references to “trusted sources.”

It looks like Google can calculate the probability of link spam based on the number of trusted sources linking to a page.
We don’t know what constitutes a “trusted source,” but when looked at holistically alongside our other findings, we can assume that this could be based on the “homepage” trust.
Can links from trusted sources effectively dilute spammy links?
It’s definitely possible.
9. Google is probably identifying negative SEO attacks and ignoring these links by measuring link velocity
The SEO community has been divided over whether negative SEO attacks are a problem for some time. Google is adamant they’re able to identify such attacks, while plenty of SEOs have claimed their site was negatively impacted by this issue.
The documentation gives us some insight into how Google attempts to identify such attacks, including attributes that consider:
- The timeframe over which spammy links have been picked up.
- The average daily rate of spam discovered.
- When a spike started.

It’s possible that this also considers links intended to manipulate Google’s ranking systems, but the reference to “the anchor spam spike” suggests that this is the mechanism for identifying significant volumes, something we know is a common issue faced with negative SEO attacks.
There are likely other factors at play in determining how links picked up during a spike are ignored, but we can at least start to piece together the puzzle of how Google is trying to prevent such attacks from having a negative impact on sites.
10. Link-based penalties or adjustments can likely apply either to some or all of the links pointing to a page
It seems that Google has the ability to apply link spam penalties or ignore links on a link-by-link or all-links basis.

This could mean that, given one or more unconfirmed signals, Google can define whether to ignore all links pointing to a page or just some of them.
Does this mean that, in cases of excessive link spam pointing to a page, Google can opt to ignore all links, including those that would generally be considered high quality?
We can’t be sure. But if this is the case, it could mean that spammy links are not the only ones ignored when they are detected.
Could this negate the impact of all links to a page? It’s definitely a possibility.
11. Toxic links are a thing, despite Google saying they aren’t
Just last month, Mueller stated (again) that toxic links are a made-up concept:
- “The concept of toxic links is made up by SEO tools so that you pay them regularly.”
In the documentation, though, we see reference given to “BadBackLinks.”

The information given here suggests that a page can be penalized for having “bad” backlinks.
While we don’t know what form this takes or how close this is to the toxic link scores given by SEO tools, we’ve got plenty of evidence to suggest that there is at least a boolean (typically true or false values) measure of whether a page has bad links pointing to it.
My guess is that this works in conjunction with the link spam demotions I talked about above, but we don’t know for sure.
12. The content surrounding a link gives context alongside the anchor text
SEOs have long leveraged the anchor text of links as a way to give contextual signals of the target page, and Google’s Search Central documentation on link best practices confirms that “this text tells people and Google something about the page you’re linking to.”
But last week’s leaked documents indicate that it’s not just anchor text that’s used to understand the context of a link. The content surrounding the link is likely also used.

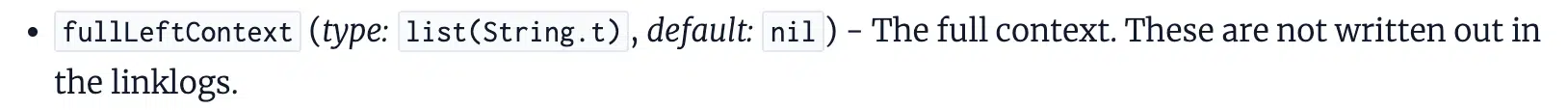

The documentation references context2, fullLeftContext, and fullRightContext, which are the terms near the link.
This suggests that there’s more than the anchor text of a link being used to determine the relevancy of a link. On one hand, it could simply be used as a way to remove ambiguity, but on the other, it could be contributing to the weighting.
This feeds into the general consensus that links from within relevant content are weighted far more strongly than those within content that’s not.
Key learnings & takeaways for link builders and digital PRs
Do links still matter?
I’d certainly say so.
There’s an awful lot of evidence here to suggest that links are still significant ranking signals (despite us not knowing what is and isn’t a ranking signal from this leak), but that it’s not just about links in general.
Links that Google rewards or does not ignore are more likely to positively influence organic visibility and rankings.
Maybe the biggest takeaway from the documentation is that relevancy matters a lot. It is likely that Google ignores links that don’t come from relevant pages, making this a priority measure of success for link builders and digital PRs alike.
But beyond this, we’ve gained a deeper understanding of how Google potentially values links and the things that could be weighted more strongly than others.
Should these findings change the way you approach link building or digital PR?
That depends on the tactics you’re using.
If you’re still using outdated tactics to earn lower-quality links, then I’d say yes.
But if your link acquisition tactics are based on earning links with PR tactics from high-quality press publications, the main thing is to make sure you’re pitching relevant stories, rather than assuming that any link from a high authority publication will be rewarded.
For many of us, not much will change. But it’s a concrete confirmation that the tactics we’re relying on are the best fit, and the reason behind why we see PR-earned links having such a positive impact on organic search success.


