

Originally Posted on Martech Zone by Douglas Karr
 That Your Content Is Indexed on Google 7")
Getting your content indexed on Google is crucial for SEO and driving organic traffic to your website. Google discovers and indexes URLs through a combination of methods, including following links, processing sitemaps, and recognizing external links. In this article, we’ll explore these methods in detail and discuss how you can expedite the crawling and indexing process.
How Google Discovers URLs
Crawlers respect the instructions in your website’s robots.txt file, which specifies which pages or directories the bots are allowed to access. By properly configuring your robots.txt file, you can grant Google permission to crawl the pages you want indexed while restricting access to sections you want to keep private. In addition to following links and respecting robots.txt, Google discovers URLs through sitemaps and external links.
- Robots.txt: Before crawling your website, Google’s bots check your robots.txt file for instructions on which pages or directories they can access. Ensure your robots.txt file is properly configured to allow crawling of the pages you want to be indexed while disallowing access to sensitive or irrelevant site sections.
- Following Links: Google’s bots, called crawlers, start with a set of known web pages and follow links on those pages to discover new ones. This is the primary way Google finds new content. Ensuring your website has a clear internal linking structure can help Google’s crawlers navigate your site more easily.
- External Links: When other websites link to your pages, it signals to Google that your content is valuable and worth crawling. Earning high-quality backlinks from reputable websites can improve your chances of getting indexed quickly.
- Sitemaps: A sitemap is an XML file that lists all the pages on your website. Submitting a sitemap through Google Search Console helps Google find and understand the structure of your website, leading to more efficient crawling. Keep your sitemap up to date as you add or remove pages from your site.
 That Your Content Is Indexed on Google 4")
Methods to Expedite Crawling and Indexing
There is no guarantee of immediate crawling or indexing. It can take anywhere from a few days to a few weeks for Google to process your requests. Be patient and continue to create high-quality content in the meantime.
- Google Search Console:
- Submit URL Inspection: Use the URL Inspection tool to check the index status of individual pages and request crawling for newly created or updated pages. This is particularly useful when you’ve made significant changes to a page and want Google to recrawl it.
- Submit Sitemaps: As mentioned, submit your sitemap to guide Google’s crawlers and ensure all important pages are discovered. You can submit your sitemap through the Sitemaps report in Google Search Console.
- Internal Linking: Ensure all pages on your website are linked together effectively, making it easier for Google’s crawlers to navigate and discover all your content. Use descriptive anchor text that accurately reflects the content of the linked page.
- Backlinks: Earn high-quality backlinks from reputable websites. This will signal to Google that your website is authoritative and worthy of crawling. Focus on creating valuable content that naturally attracts links from other websites in your niche.
Focus on creating high-quality, unique content that provides value to users. This will naturally attract more links and encourage Google to crawl and index your website more frequently. Avoid duplicate content and low-quality pages that may hurt your overall indexing.
Verifying URL Indexation
Indexing, in the context of search engines like Google, refers to the process of adding web pages into the search engine’s database. When a web page is indexed, it becomes a part of the search engine’s vast repository of information, making it possible for users to find that page through relevant search queries. Key points about indexing:
- Discovery: Before a web page can be indexed, it needs to be discovered by the search engine’s crawlers (also known as bots or spiders). Crawlers follow links on known pages to find new URLs.
- Processing: Once a page is discovered, the search engine downloads its content and analyzes various factors like the page’s content, structure, and links to understand its relevance and context.
- Storage: After processing, the page’s content and associated metadata are stored in the search engine’s index, a massive database of web pages.
- Retrieval: When a user enters a search query, the search engine algorithms quickly scan the index to find the most relevant pages matching the query and present them in the search results.
- Freshness: Search engines continuously update their index by recrawling and reprocessing pages to ensure the information remains fresh and relevant.
Indexing is a crucial part of how search engines organize and retrieve information from the Internet, enabling users to find relevant web pages quickly and efficiently.
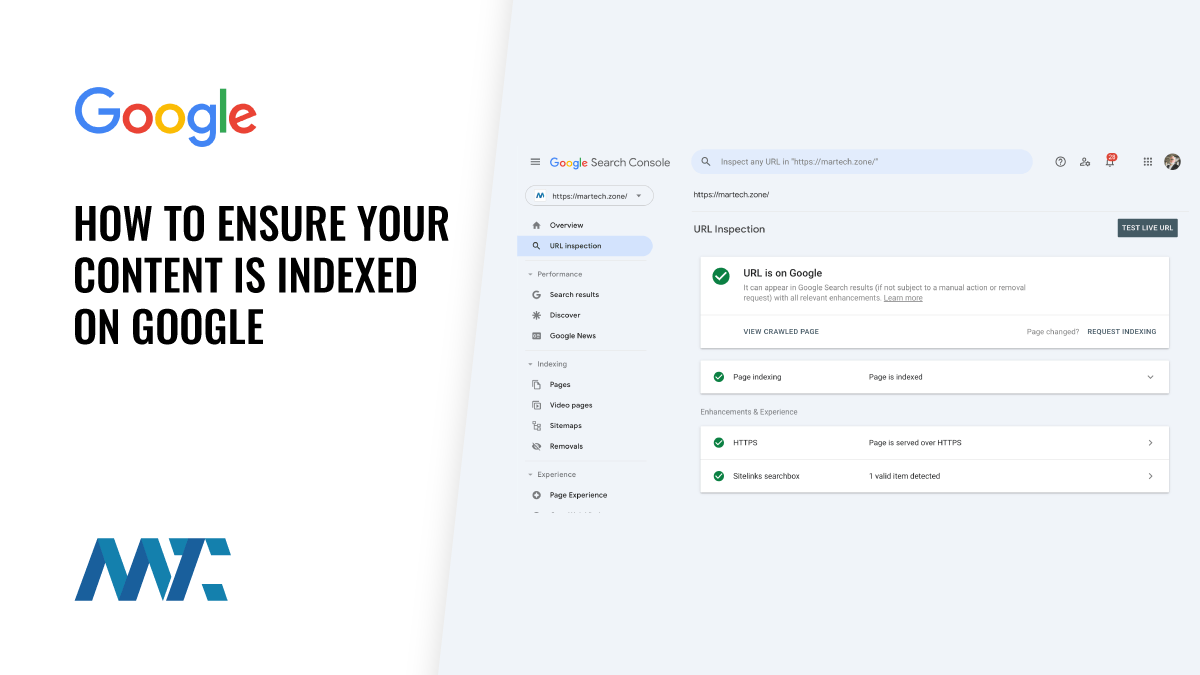
To check if a specific URL is indexed in Google, follow these steps:
- Open Google Search Console and navigate to the URL Inspection tool.
- Enter the URL you want to check and click Search.
- If the URL is indexed, you’ll see a message that says URL is on Google.
 That Your Content Is Indexed on Google 5")
- If the URL is not indexed, you’ll see a message that says URL is not on Google. In this case, you can request indexing by clicking the Request Indexing button.
 That Your Content Is Indexed on Google 6")
Alternatively, you can perform a site: search using Google. For example, to check if https://martech.zone is indexed, search for site:https://martech.zone in Google. If the URL appears in the search engine results page (SERP), it is indexed.
By understanding how Google discovers and indexes content, implementing best practices for expediting the process, and regularly monitoring your indexation status, you can ensure that your valuable content is quickly found and ranked by Google.
©2024 DK New Media, LLC, All rights reserved.
Originally Published on Martech Zone: How to Ensure (And Verify) That Your Content Is Indexed on Google


